Princípios Básicos de Computação Gráfica 3D Aplicada às Ciências da Saúde¶

Visão com e sem os óculos 3D polarizados.¶
Introdução¶
Este capítulo se trata de um material introdutório, criado para o nosso curso presencial e online de “Princípios Básicos de Computação Gráfica 3D Aplicada às Ciências da Saúde”. Inicialmente o objetivo era desenvolvermos uma metodologia de planejamento cirúrgico utilizando apenas software livre e gratuito. Os trabalhos foram bem sucedidos e resolvemos compartilhar os resultados com a comunidade de cirurgia ortognática. Assim que postamos os primeiros conteúdos relacionados às pesquisas em nossas mídias sociais, a procura foi grande e não se limitou apenas aos profissionais da Odontologia, mas estendeu-se a todos os campos da saúde humana e também veterinária. Em face dessa procura, decidimos abrir o conteúdo inicial e teórico dos tópicos que abordam o nosso curso (que é consideravelmente prático). Assim, os eventuais interessados poderão aprender um pouco acerca dos conceitos envolvendo o treinamento, ao passo que aqueles curiosos da área de computação gráfica, terão ao alcance das mãos um material que os introduzirá ao campo da modelagem e digitalização nas ciências da saúde.
Esperamos que apreciem, boa leitura!
Você Já Sabe Muito do que Precisa¶
O que é necessário para aprender a trabalhar com 3D?
Se você é uma pessoa que sabe operar um computador e ao menos já editou um texto, a resposta é, pouca coisa. Ao editar um texto nós utilizamos o teclado para entrar com as informações, ou seja, as palavras. O teclado nos auxilia com os atalhos, por exemplo os popularíssimos CTRL+C e CTRL+V para copiar e colar. Perceba que não usamos o menu do sistema para acionar esses comandos por um motivo muito simples, é muito mais rápido e prático fazê-los pelas teclas de atalho. Ao escrever um texto nós não nos limitamos a compor uma frase ou redigir uma página. Quase sempre formatamos as letras, deixando-as em negrito, setando-as como título ou inclinando-as e importamos imagens ou gráficos. Essas últimas ações também podem ser chamadas de interoperabilidade. O nome é complexo, mas o conceito é simples. Interoperabilidade é, grosso modo, a capacidade que os programas têm de trocarem informações uns com os outros. Ou seja, você tira a foto de uma câmera, salva ela no PC, talvez use um editor de imagens para aumentar o contraste, depois importa essa imagem no seu documento. Ora, a imagem foi criada e editada em outros lugares, isso é interoperabilidade! O mesmo acontece com uma tabela, que pode ser feita em um editor de planilhas e importada posteriormente no editor de texto. Esse montante de conhecimento não é trivial, assim sendo, poderíamos dizer que você já conta com 75% de todas as habilidades computacionais necessárias para trabalhar com modelagem 3D. Agora, se você é daqueles que jogam ou já jogaram um game de tiro em primeira pessoa, pode ter certeza que conta com 95% de tudo o que precisa para modelar em 3D. Como isso é possível? Muito simples. Além de todo o conhecimento envolvendo a maioria dos programas de computador, como já citados, o jogador ainda desenvolve outras capacidades inerentes ao campo da computação gráfica 3D. Ao jogar nessas plataformas é necessário antes de tudo analisar a cena a qual se vai interagir. Depois de estudar o campo de atuação, o jogador se desloca pela cena e se aparecer alguém na reta a chance desse indivíduo levar um tiro é bem grande. Essa habilidade de se deslocar e interagir em um ambiente 3D é a peça inicial para se trabalhar com um programa de modelagem e animação.
Observação e Deslocamento pela Cena¶
Quando chegamos a um local desconhecido, a primeira coisa que fazemos é observar. Imagine que você vai fazer um curso em um determinado espaço. Dificilmente alguém “chega chegando” em um ambiente assim. Antes de tudo nós observamos a cena, fazemos um apanhado geral do número de pessoas e até estudamos as rotas de fuga caso aconteça algum imprevisto muito sério. Em seguida nos deslocamos pela cena estudada, indo até o local onde aguardaremos o início das atividades. Em um terceiro momento, nós interagimos com o cenário, tanto utilizando os equipamentos do curso como caderno e caneta, quanto conversando com outros alunos e/ou professores.
Veja que o evento foi marcado por três fases:
Observação;
Deslocamento;
Interação.
No mundo virtual da computação gráfica a sequência é praticamente a mesma. A primeira parte do processo consiste em observar a cena, em ter uma idéia de como ela é. Esse comando é conhecido como Orbit. Ou seja, um observador orbita (Orbit) a cena observando-a, como se fosse um satélite artificial em torno da terra. Ele mantém uma distância fixa e pode ver a cena de todos os ângulos possíveis. Mas, nem só de orbitação vive o homem, é preciso aproximar-se para ver os detalhes de algum ponto específico. Para isso utilizamos os comandos de zoom, já bem conhecidos da maioria dos operadores de computador. Além da aproximação e afastamento (+ e – zoom) você também precisa caminhar pelas cenas ou mesmo deslocar-se horizontalmente (movimento conhecido como Pan). Um fato curioso sobre esses comandos de observação de cena, é que quase sempre se concentram nos botões do mouse. Veja a Tabela Comparada de Comandos de Zoom.
Blender |
InVesalius |
MeshLab |
|
|---|---|---|---|
Orbitar |
Clica scroll mouse |
Bot. esq. mouse |
Bot. esq. mouse |
+- Zoom |
Roda scroll mouse |
Roda scroll mouse |
Roda scroll mouse |
Pan |
Shift + clica scroll mouse |
Clica scroll mouse |
Clica scroll mouse |
Temos acima o comparativo de três programas sobre os quais abordaremos mais à frente. O importante agora é saber que, nos três comandos básicos de zoom nós vemos o envolvimento direto do mouse. Isso deixa bem claro que, se você se deparar com uma cena 3D aberta e usar essas combinações de comandos, pelo menos deslocar o observador você vai conseguir. A frase “deslocar o observador” foi posta em negrito para que você se atente a uma situação. Até agora estamos tratando apenas de comandos de observação. Pela característica de seu funcionamento, ele pode muito bem ser confundido com o comando de rotação do objeto. Como diriam alguns, “uma coisa é uma coisa e outra coisa é outra coisa”, é muito comum que os iniciantes nessa área se confundam entre um e outro.

Diferença entre Orbit e Rotate.¶
Para ilustrar bem a diferença entre eles, observe na figura de exemplo (Fig. 2) a cena ao centro (Original) que se trata da referência inicial. À esquerda nós observamos o comando de orbitar em ação (Orbit). Veja que o elemento grid (em cinza claro) que é referência do que seria o chão da cena acompanha o cubo. Isso acontece porque na verdade quem se desloca na cena é o observador e não os elementos. Já à direita (Rotate) vemos o grid na mesma posição que na cena ao centro, ou seja, o observador se manteve no mesmo ponto, só que o cubo sofreu rotação.
Por que isso parece confuso?
No mundo real, aquele que vivemos, o observador é… você. Você usa os seus olhos para ver o espaço com toda a profundidade tridimensional que esse sistema binocular natural oferece. Quando trabalhamos com um software de modelagem e animação 3D, os seus olhos passam a ser a 3D View, ou seja, a janela de trabalho onde a cena está sendo apresentada. No mundo real quando vamos caminhar por um espaço, nós temos o chão para nos deslocar. Ele é a nossa referência. Em uma cena 3D geralmente esse chão inicial é representado pelo grid que vimos na figura de exemplo. Sempre é importante ter uma referência para se trabalhar, caso contrário fica quase impossível, principalmente para quem está começando, conseguir fazer alguma coisa no computador.
Formas de Visualização¶
“A televisão engorda”.
Com certeza você já ouvir essa frase em alguma entrevista ou até de algum conhecido ou conhecida que já fora filmado e viu o resultado na tela. De fato, pode acontecer da pessoa parecer mais robusta do que o “normal”, mas a resposta é que todos nós somos mais robustos do que a estrutura que os nossos olhos nos apresentam quando nos fitamos frente ao espelho. Para que você tenha uma noção clara do que isso significa, é preciso compreender alguns conceitos simples que envolvem a visualização a partir de um observador em um programa de modelagem e animação 3D. O observador nesse caso é representado por uma câmera.

Representações gráficas de uma câmera.¶
Curiosamente, uma das representações mais usadas para a câmera dentro de uma cena 3D é o ícone de uma pirâmide. Veja na imagem (Fig. 3), onde são apresentados três exemplos. Tanto o software Blender 3D, quanto o MeshLab contam com um ícone em forma de pirâmide para representar a câmera no espaço. A forma mais simples de representar essa estrutura pode ser um triângulo, como o que aparece à direita (Icon). Tudo isso não é à toa. Essa representação guarda em si os princípios básicos da fotografia. Você já deve ter ouvido de falar da câmera pinhole [A6]. Em uma tradução livre significa câmera fotográfica de orifício. O funcionamento desse dispositivo é muito simples, trata-se de uma câmera arcaica feita com uma pequena caixa ou lata. Em um lado ela apresenta um orifício bem fino e no outro lado é colocado um papel fotográfico. O furo fica tampado por uma fita adesiva escura até o fotógrafo em questão posicionar a câmera em um ponto. Uma vez que a câmera esteja posicionada e imóvel, a fita é retirada e o filme recebe a luz externa por um tempo. Em seguida o orifício é novamente tampado, a câmera é transportada até um estúdio e o filme revelado apresentando a cena em negativo. Tudo simples e funcional.
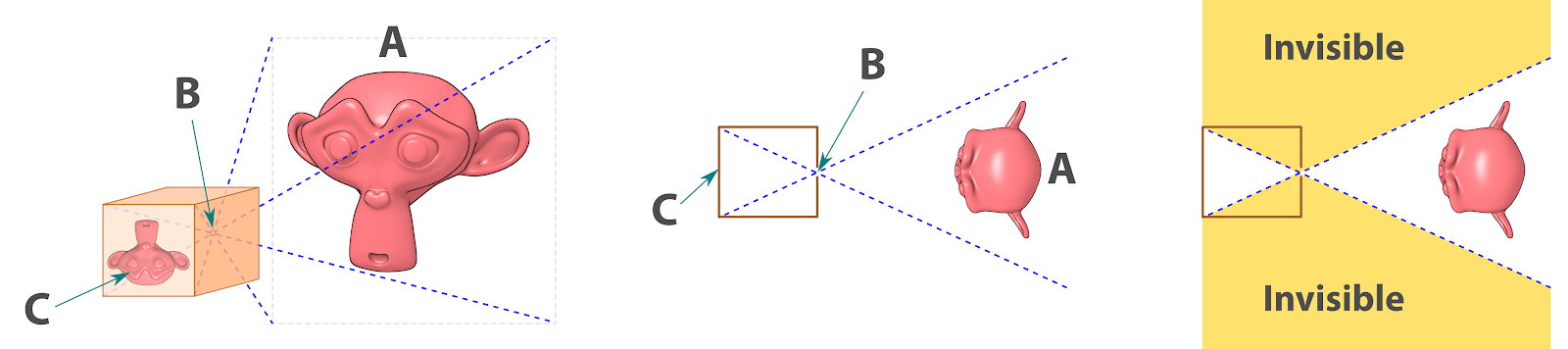
Exemplo esquemático dos limites de visualização de uma câmera simples.¶
Para nós o que interessa mesmo são alguns pequenos detalhes (Fig. 4). Imagine que temos um objeto a ser fotografado (A), a luz que vem de fora entra na câmera por um orifício feito na parte frontal (B) e projeta a imagem invertida dentro da caixa (C). Tudo o que estiver fora dessa área de captura ficará invisível (ilustração à direita).
Área de captura da câmera.¶
Nessa altura já temos a resposta do porquê os ícones de câmera serem semelhantes em programas diferentes. A pirâmide representa a projeção da área visível da câmera (Fig. 5). Atente-se que projeção da área visível não o mesmo que TODA a área visível, ou seja, temos uma pequena apresentação de como a câmera recebe a cena externa.
Exemplo de limite de captura.¶
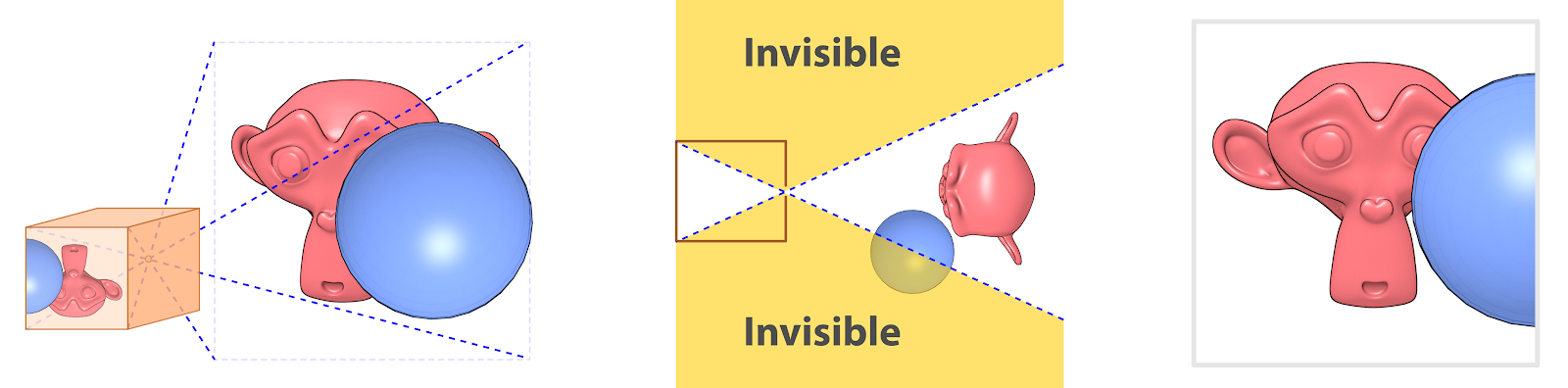
Tudo o que estiver fora dessa projeção simplesmente não aparecerá na cena, como no caso da esfera, que está parcialmente oculta (Fig. 6). Mas ainda falta uma peça nesse quebra-cabeça, o motivo de parecermos mais robustos para as câmeras de TV.
Imagens capturadas com distâncias focais diferentes.¶
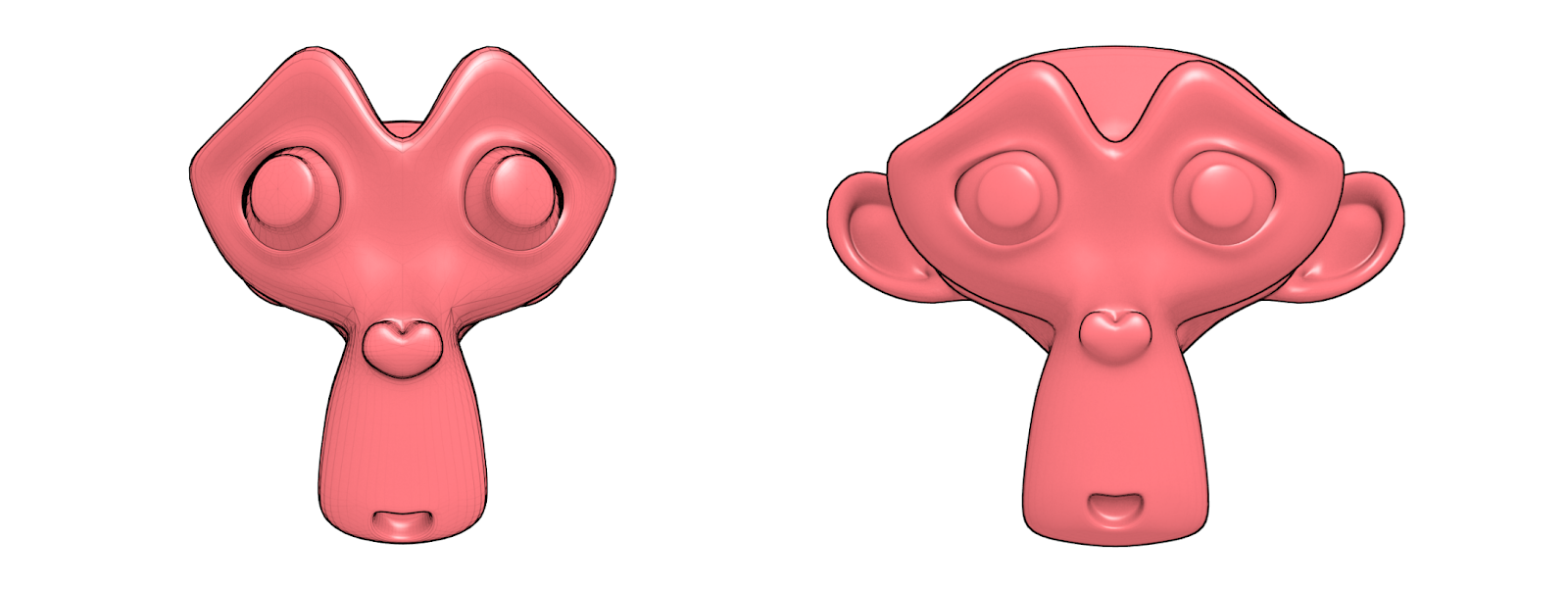
Observe as duas figuras que estão lado-a-lado (Fig. 7), mirando uma em relação a outra, podemos identificar algumas características que as diferenciam. A imagem à esquerda parece tratar-se de uma estrutura que está sendo espremida, ainda mais quando vemos os olhos que parecem saltar para os lados. Já à direita, temos uma estrutura que, em relação à outra, parece ter os olhos mais centrados, o nariz menor, a boca mais aberta e um pouco mais para cima, vemos as orelhas despontando e a parte superior da cabeça é notoriamente maior. As duas estruturas têm bastante diferenças visuais… mas se tratam de um mesmo objeto em 3D! A diferença mora na forma em que as fotografias foram feitas. Nesse caso, utilizou-se duas distâncias focais diferentes.
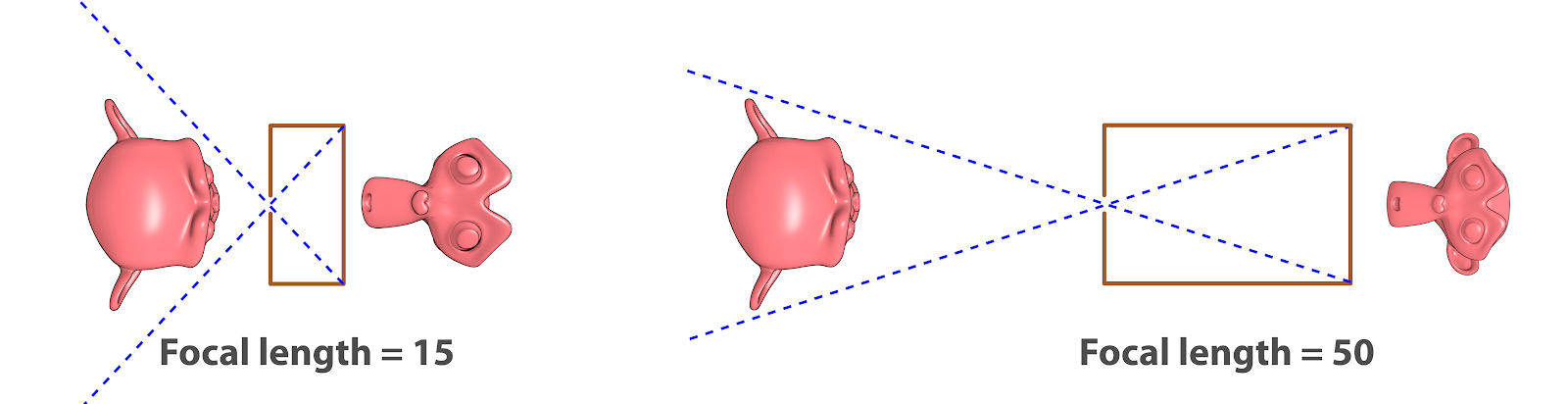
Exemplo de distâncias focais diferentes.¶
Na outra ilustração (Fig. 8) nós vemos as duas câmeras pinhole em topo. A imagem à esquerda indica o valor de distância focal (focal length) de 15 e à direita vemos o valor da distância focal de 50. De um lado vemos uma estrutura mais compacta (15), onde o fundo está bem próximo a parte da frente e no outro uma estrutura mais esticada, com um ângulo de captura mais fechado (50). Mas porque neste caso da distância focal 15, as orelhas não aparecem na cena?
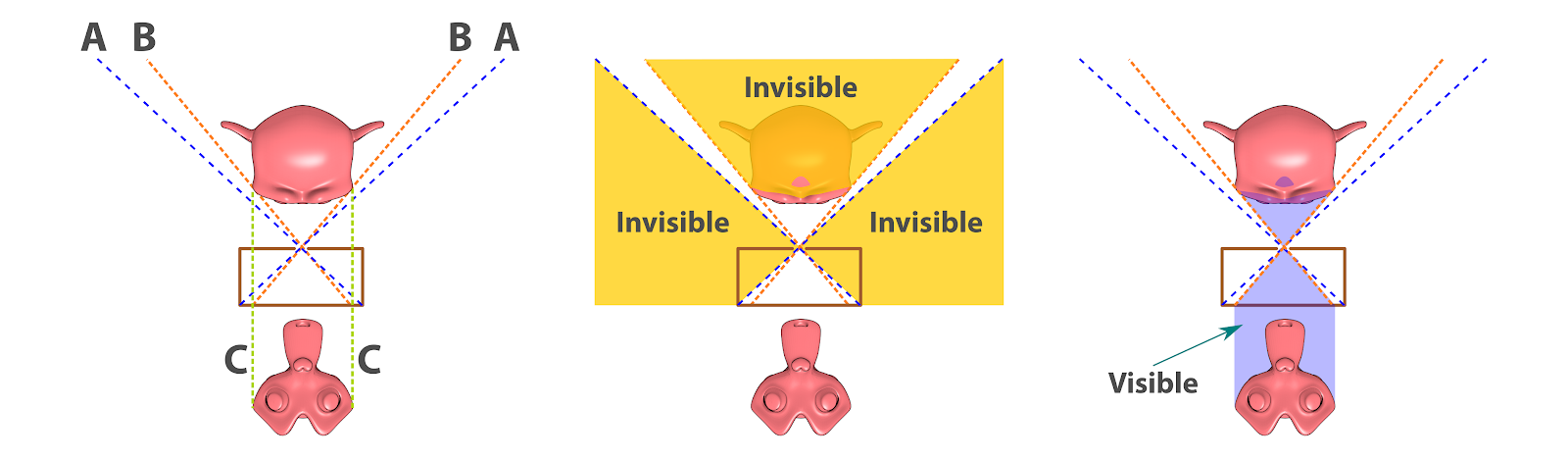
Projeção das estruturas visíveis e invisíveis.¶
A explicação é simples e pode ser abordada de modo geométrico (Fig. 9). Veja que para enquadrar a estrutura na foto foi necessário aproximá-la bastante do orifício de entrada de luz. Ao fazer isso, o volume capturado (BB) pega apenas a parte frontal da face, ocultando as orelhas (Invisible). Ao final, temos uma projeção limitada (CC) que sofre ainda certa deformação, dando a impressão dos olhos estarem levemente saltados.
Projeção das estruturas visíveis.¶
Com a distância focal de 50 a área visível da face é mais ampla. Podemos atestar isso com a projeção da região visível, como fizemos anteriormente (Fig. 10).
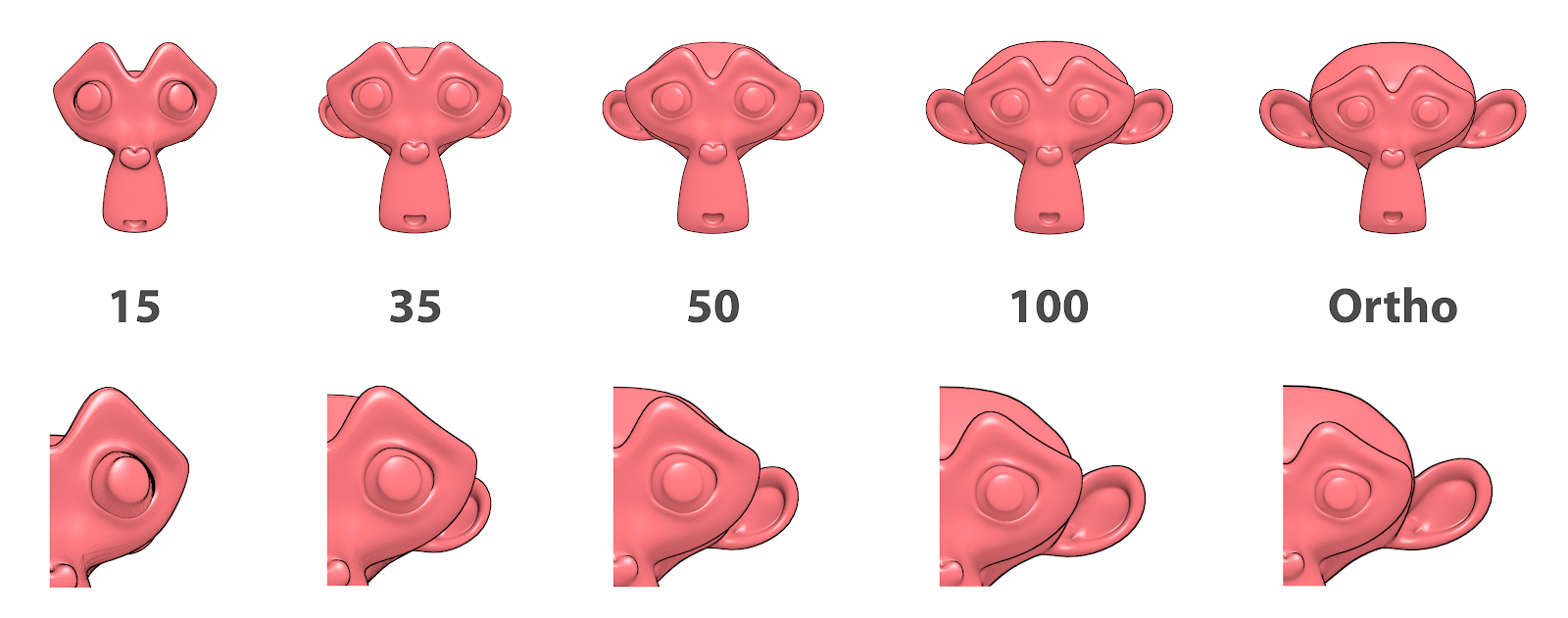
Distâncias focais diferentes.¶
Na ilustração de exemplo (Fig. 11) optou-se por enquadrar a estrutura bem próxima aos limites da captura da câmera e desse modo evidenciar as diferenças de captação. Assim podemos ver claramente como um valor maior de distância focal implica em uma captura mais ampla da estrutura fotografada. Um bom exemplo é que, com o valor 15 vemos muito discretamente as pontas inferiores das orelhas, em 35 as estruturas já despontam, em 50 vê-se quase o dobro da área e em 100 temos uma visão quase completa das orelhas. Note ainda que em 100, a região marginal dos olhos transpassa a estrutura da cabeça e em ortogonal (Ortho) a região marginal dos olhos está alinhada com a mesma estrutura.
Mas, o que vem a ser uma vista ortogonal?
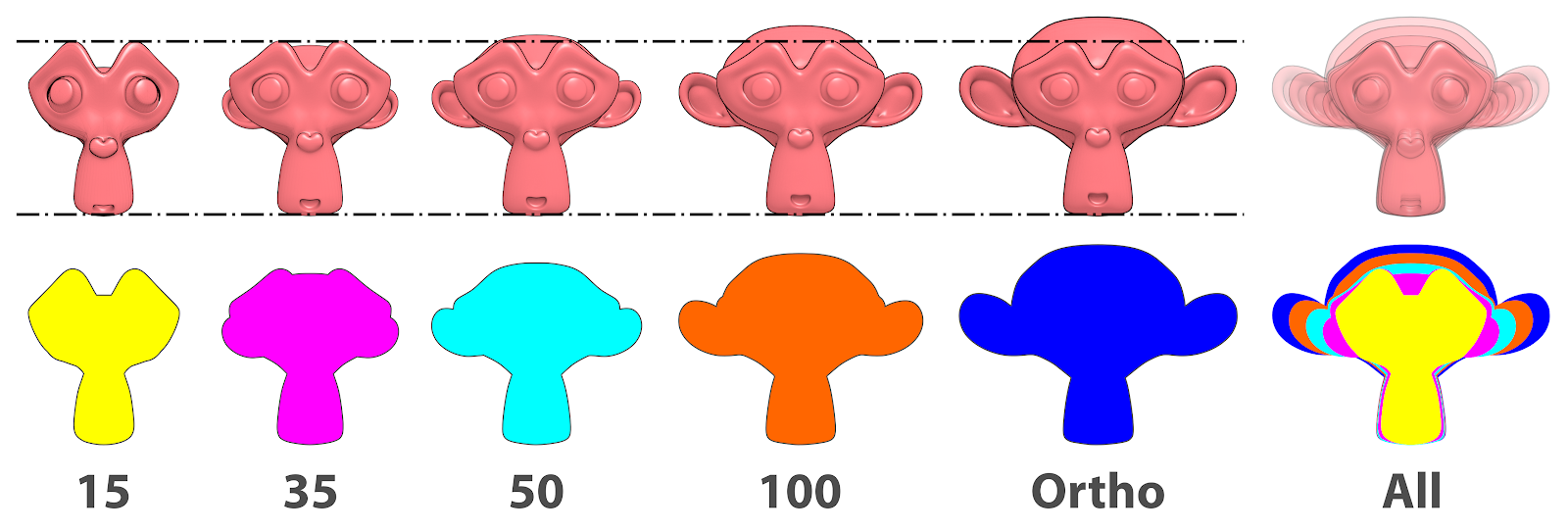
Comparação das arestas visíveis.¶
Para uma compreensão ser mais completa, vamos por partes. Se isolarmos as arestas de todas as vistas (Fig. 12), alinharmos pelas sobrancelhas e base do queixo e colocarmos as formas sobrepostas, veremos ao final que quanto menor a distância focal, menor a área estrutural visualizada. Dentre todas as formas a que mais se destaca é justamente a visualização ortogonal. Ela simplesmente tem mais área do que todas as outras. Vemos isso à extrema direita ao atestar a cor azul despontando nas regiões marginais da sobreposição.
Mas, e a projeção ortogonal, como funciona?
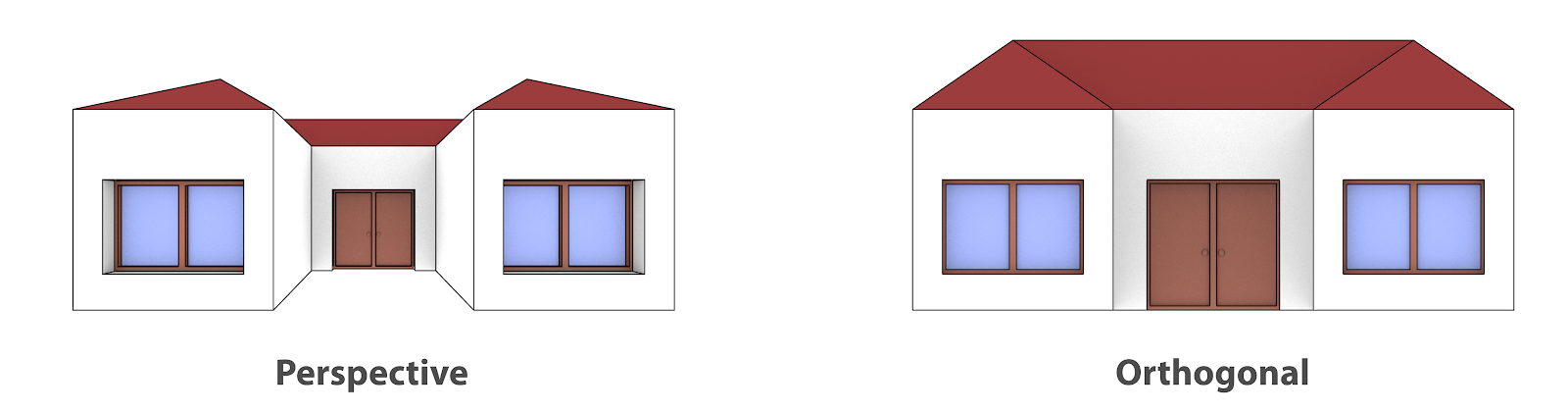
Comparação Perpective vs. Orthogonal.¶
O melhor exemplo é a fachada de uma casa (Fig. 13), à esquerda temos uma visão com distância focal 15 (Perspective) e à direita em ortogonal (Orthogonal).
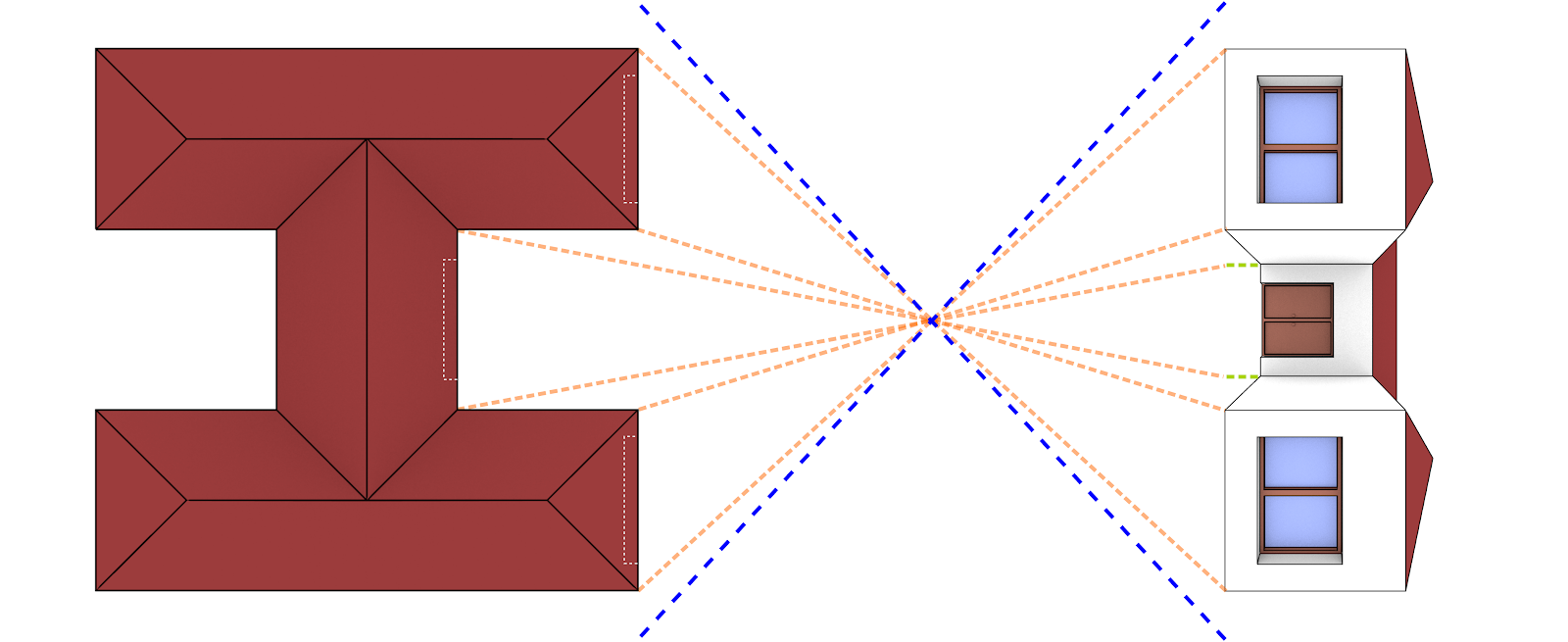
Projeção da perspectiva.¶
Analisando a captura com distância focal 15 (Fig. 14), temos as linhas em azul, como de praxe, representando o limite da área visível (limite da imagem gerada) e nas demais linhas a projeção de algumas partes-chave da estrutura.
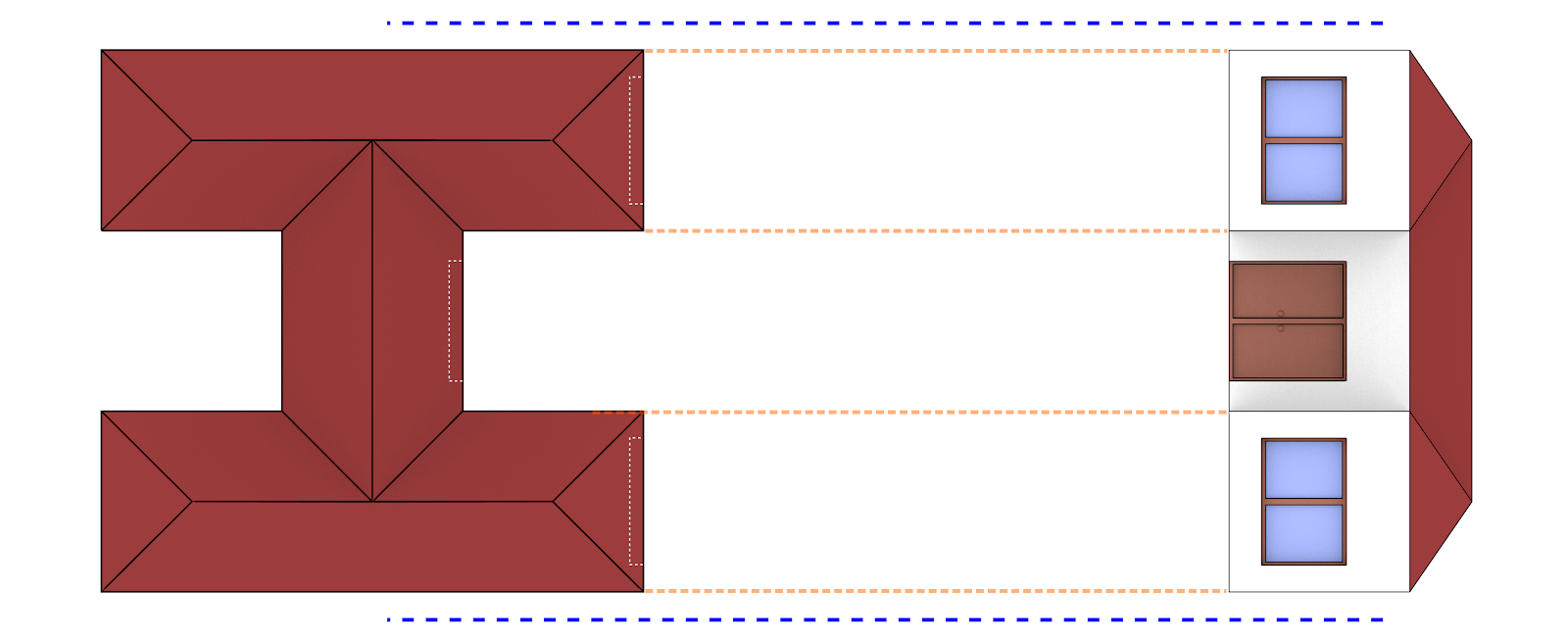
Projeção ortogonal.¶
A visão ortogonal por sua vez não sofre a deformação da distância focal (Fig. 15). Ela simplesmente recebe as informações estruturais diretamente, gerando um gráfico condizente com as medidas do original, ou seja, ela mostra a casa “como ela é”. O processo lembra muito a projeção de raio-x, que representa a estrutura radiografada quase sem deformação de perspectiva.
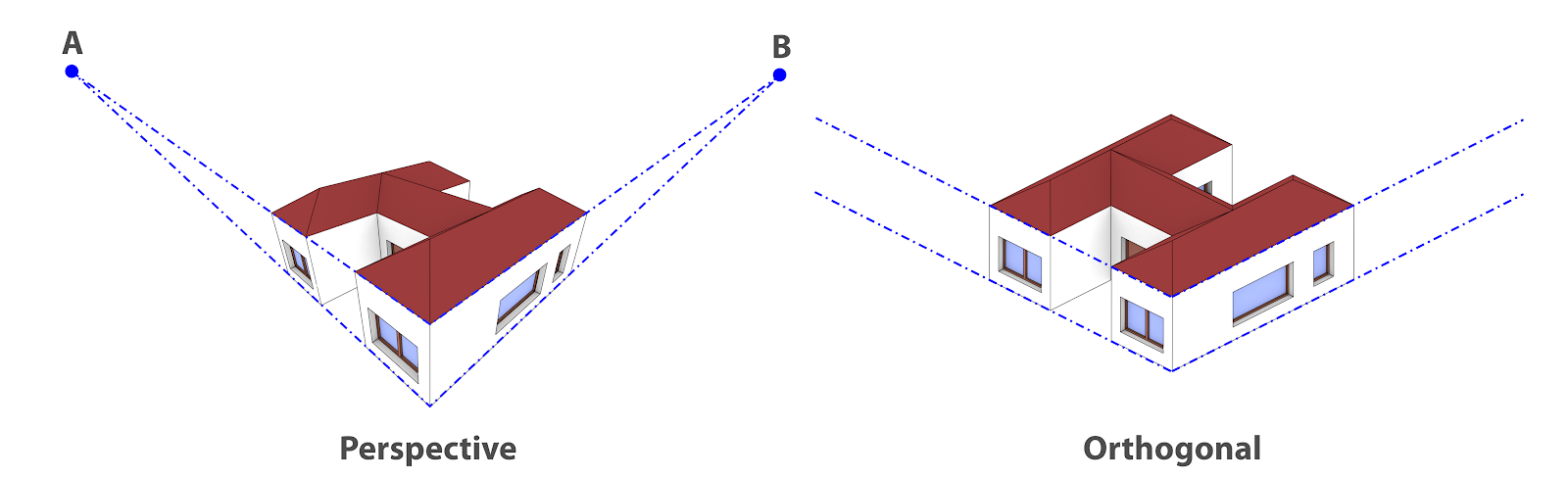
Comparação das linhas de projeção nos limites da perspectiva e da ortogonal.¶
Olhando as imagens de comparação (Fig. 16), a partir de outro ponto de vista, é possível atestar uma diferença marcante entre elas. A parte de baixo e de cima das paredes laterais são paralelas, mas se traçarmos uma linha em cada uma dessas partes na perspectiva, esse traçado vai acabar se encontrando numa intersecção que é conhecida como ponto de fuga (A e B). No caso da vista ortogonal, as linhas não se encontram, porque… são paralelas! Ou seja, novamente vemos que a projeção ortogonal respeita a estrutura real do objeto.
Então quer dizer que a visão ortogonal sempre é a melhor opção?
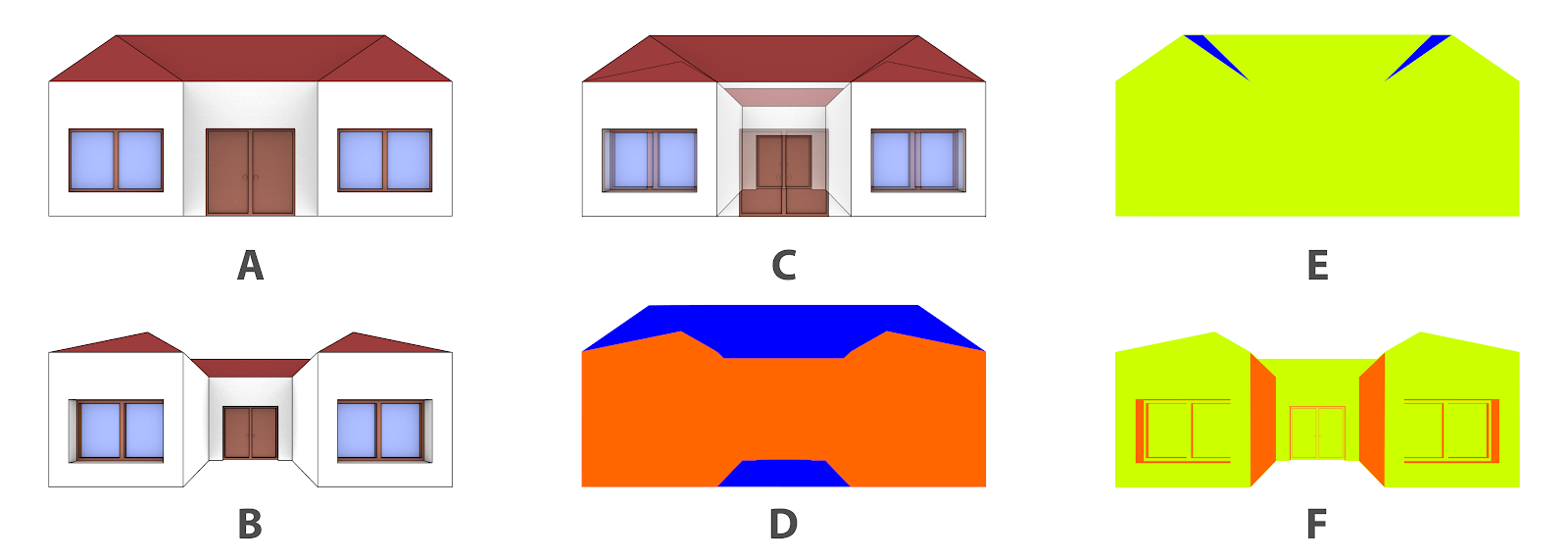
Comparação das regiões visíveis da perspectiva e da ortogonal.¶
Não, não é sempre a melhor opção, porque tudo depende do que você está fazendo. Tomemos como exemplo as visualizações frontais, abordadas anteriormente (Fig. 17). Mesmo que a vista ortogonal ofereça uma área maior de captura (D) se compararmos as regiões exclusivas da ortogonal (E) com as regiões exclusivas visualizadas pela perspectiva de distância focal 15 (F), atestaremos que, mesmo cobrindo uma área em pixels menor, a vista com deformação de perspectiva contemplou regiões que ficaram ocultas na vista ortogonal.
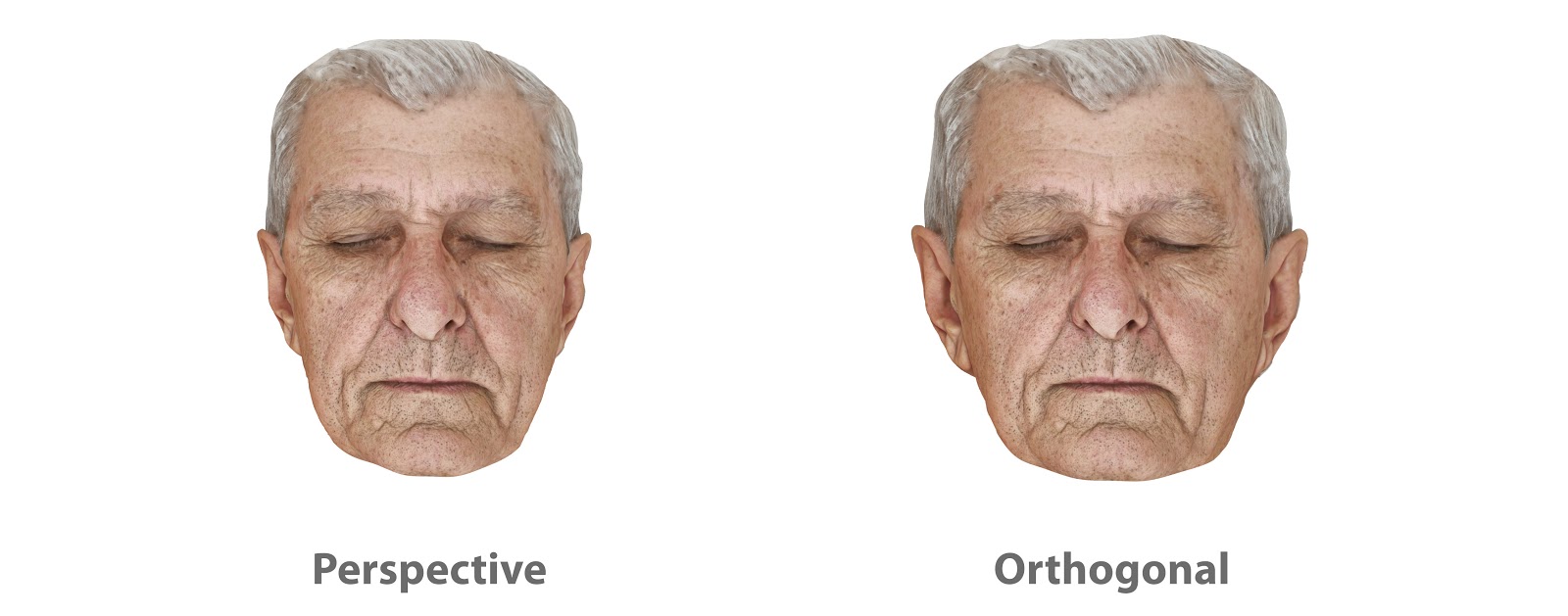
Comparação de uma face com perspectiva e ortogonal.¶
Isso responde a pergunta sobre a TV engordar ou não as pessoas. Quanto maior a distância focal, mais robusta é a aparência do rosto (Fig. 18). Mas isso não significa engordar ou não, mas sim mostrar de fato a sua estrutura, ou seja, a imagem ortogonal é o indivíduo em suas medidas mais coerentes com a volumetria real. O interessante desse aspecto é que ele mostra que “os olhos nos enganam”, a imagem que vemos das pessoas não corresponde ao que de fato eles são estruturalmente falando, logo, o que vemos no espelho também não. Os fotógrafos profissionais, por exemplo, sabem bem como explorar essa realidade e extrair o máximo de qualidade em suas obras.
Visão 3D¶
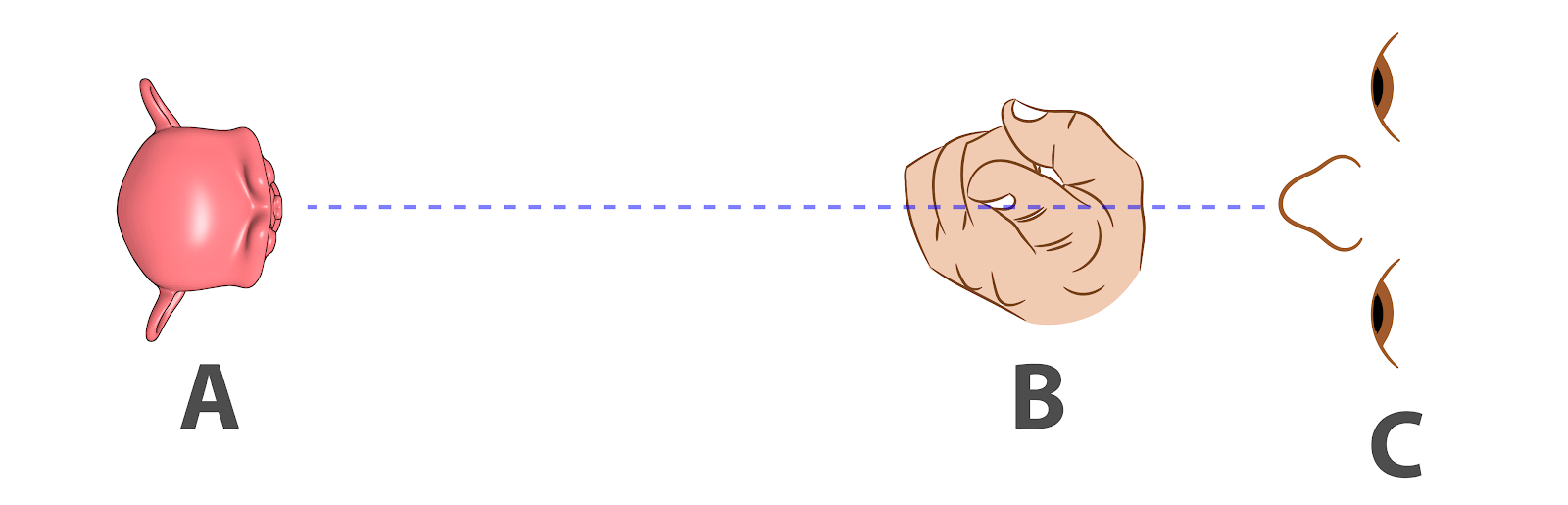
Exercício de visualização 3D.¶
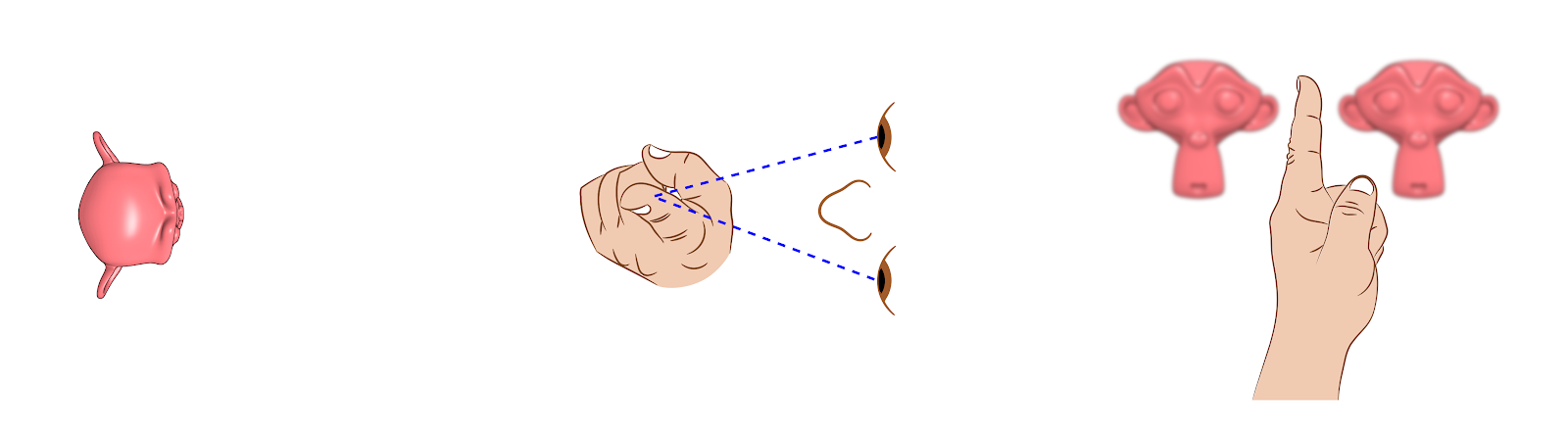
Procure um objeto pequeno para fitar (A), que esteja a mais ou menos um metro de distância. Posicione o indicador (B) apontando para cima a 15cm da frente dos olhos (C), alinhado com o nariz (Fig. 19).
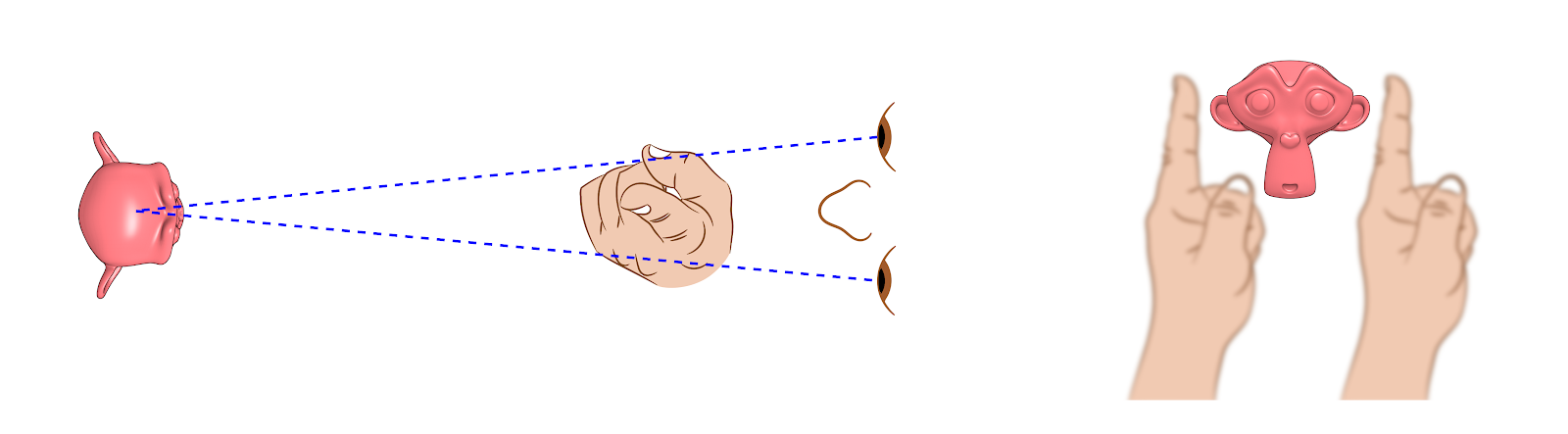
Foco no objeto.¶
Ao olhar para o objeto você verá um objeto e dois dedos (Fig. 20).
Foco no dedo.¶
Ao olhar para o dedo, você verá um dedo e dois objetos (Fig. 21).
Foco monocular, esquerdo e direito.¶
Se você observar com apenas um dos olhos, atestará que cada um tem uma visão distinta da cena (Fig.22).
Essa é uma forma bem simples de testar os limites do sistema binocular de visualização característicos dos humanos. Também fica bem claro o motivo dos pintores clássicos fecharem um dos olhos ao medir as proporções de um objeto com o pincel, de modo a replicá-la na tela. Se eles usassem os dois olhos simplesmente não funcionaria! [A7]
Você deve estar se perguntando como conseguimos enxergar apenas uma imagem com os dois olhos. Para compreender um pouco melhor esse mecanismo, vamos tomar como exemplo o cinema 3D.
O que acontece se você olha para uma tela de cinema 3D sem os óculos polarizados?

Imagem projetada visualizada sem os óculos 3D.¶
Algo parecido como a imagem de exemplo (Fig. 23), uma distorção muito conhecida daqueles que já exageraram em bebidas alcoólica. No entanto, mesmo parecendo o oposto, não há nada de errado com essa imagem.
Visão com e sem os óculos 3D polarizado.¶
Ao colocar os óculos, cada lente recebe as informações relacionadas ao seu olho. Temos então duas imagens distintas, como quando piscamos para ver com apenas um dos lados (Fig. 24).
Vamos refletir um pouco. Se a imagem borrada entra pelos óculos e se converte em parte do cenário, transportando-nos para dentro dos filmes a ponto de nos assustarmos com detritos de explosões que parecem ser projetados para cima da gente… pode ser que, as informações que recebemos do mundo sejam imagens borradas com essa. Só que, lá dentro do cérebro, em algum lugar acontece uma “mágica” que em vez de mostrar esse desfoque, as duas imagens se juntam e formam apenas uma.
Mas por que duas imagens, porque dois olhos?
A resposta está justamente na parte dos detritos da explosão que vêm ao nosso encontro. Se você assistir a mesma cena com apenas um dos olhos, os objetos não “pulam” em cima de você. Isso acontece porque a visão estereoscópica (com os dois olhos) lhe dá o poder de percepção da profundidade do ambiente. Ou seja, a noção de espaço que temos deve-se a nossa visão binocular, sem ela, ainda que tenhamos noção do ambiente por conta da perspectiva, em muito perderemos a capacidade de mensurar o seu volume.
Para que você entenda melhor a questão da profundidade da cena, criamos um exemplo que aborda de modo objetivo a questão da profundidade relacionada aos olhos (Fig. 25).

Disposição de objetos em uma cena 3D.¶
Se fosse perguntado a um grupo de indivíduos, qual dos dois objetos está mais à frente da cena, é quase certo que grande parte dos entrevistados responderia que é o objeto à esquerda.

Disposição de objetos visto pela lateral.¶
Entretanto, nem tudo é o que parece. O objeto à esquerda está mais distante (Fig. 26). Esse exemplo ilustra bem como podemos ser enganados pela visão monocular ainda que seja em perspectiva.
Não seria mais fácil que os programas de modelagem e animação oferecessem suporte a visualização estereoscópica?
De fato poderia ser, mas os programas mais populares ainda não oferecem essa possibilidade. Em face da popularização dos óculos de realidade virtual e a convergência das interfaces gráficas, vislumbra-se a possibilidade desse nicho contar com suporte pleno para a visualização estereoscópica na fase de produção. No entanto, essa possibilidade é mais uma projeção futura do que uma realidade presente e as interfaces de hoje ainda contam com muitos elementos que remontam décadas atrás.
É por esses e outros motivos que precisamos da ajuda de uma visão ortogonal quando trabalhamos em um software 3D.
Se pot um lado ainda não contamos com soluções acessíveis de visualização 3D com profundidade, por outro podemos contar com ferramentas robustas testadas e aprovadas por anos e anos de desenvolvimento. Em 1963, por exemplo, foi desenvolvido no MIT o editor gráfico Sketchpad [A4]. De lá para cá a forma de abordar objetos 3D em uma tela digital não mudou muita coisa.
O mais importante de tudo isso, é que a técnica funciona muito bem e com um pouco de treinamento você se adapta tranquilamente a metodologia, a ponto de esquecer que um dia já teve dificuldades com isso.
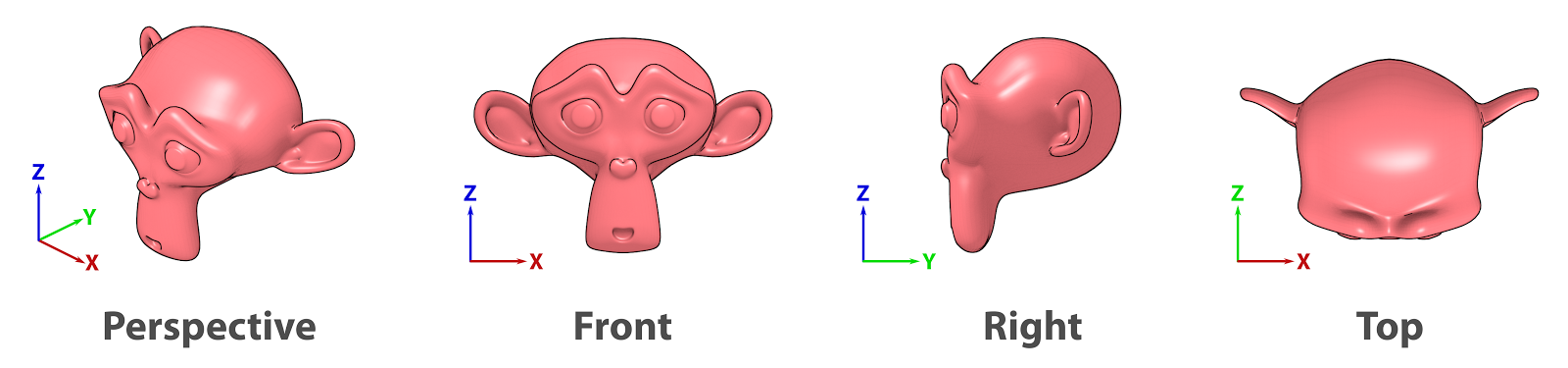
Pontos de vista.¶
Quase todos os programas de modelagem, de modo semelhante ao Sketchpad, oferecem a possibilidade de dividir a área de trabalho em quatro vistas: Perspectiva, frente, direita e topo (Fig. 27).
Mesmo não se tratando de uma perspectiva da qual contamos com a noção de profundidade, e mesmo as outras vistas sendo uma espécie de “fachada” do cenário, o que temos ao final é um ideia bem clara da estrutura da cena e do posicionamento dos objetos.Se por um lado dividir a cena em quatro partes reduz a área visual de cada vista, por outro o especialista pode optar alterar essas vistas na área total do monitor. Com o tempo, o usuário vai se especializando em trocar o ponto de vista utilizando as teclas de atalho, de modo a completar a informação necessária e não cometer erros na composição da cena.
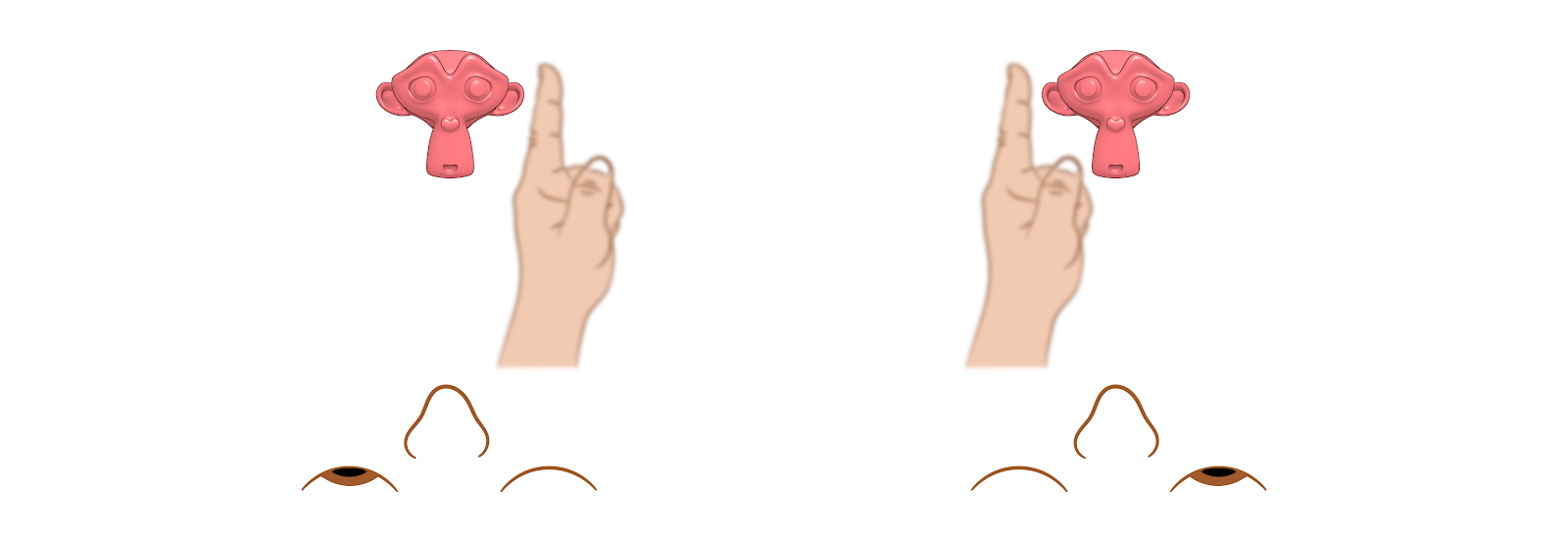
Uma amostra da versatilidade da orientação 3D a partir de vistas ortogonais é o exercício do “chapéu no macaquinho” repassado a alunos iniciantes de modelagem tridimensional. Esse exercício consiste em solicitar aos alunos que coloquem um chapéu (cone) sobre a primitiva Monkey (macaco).
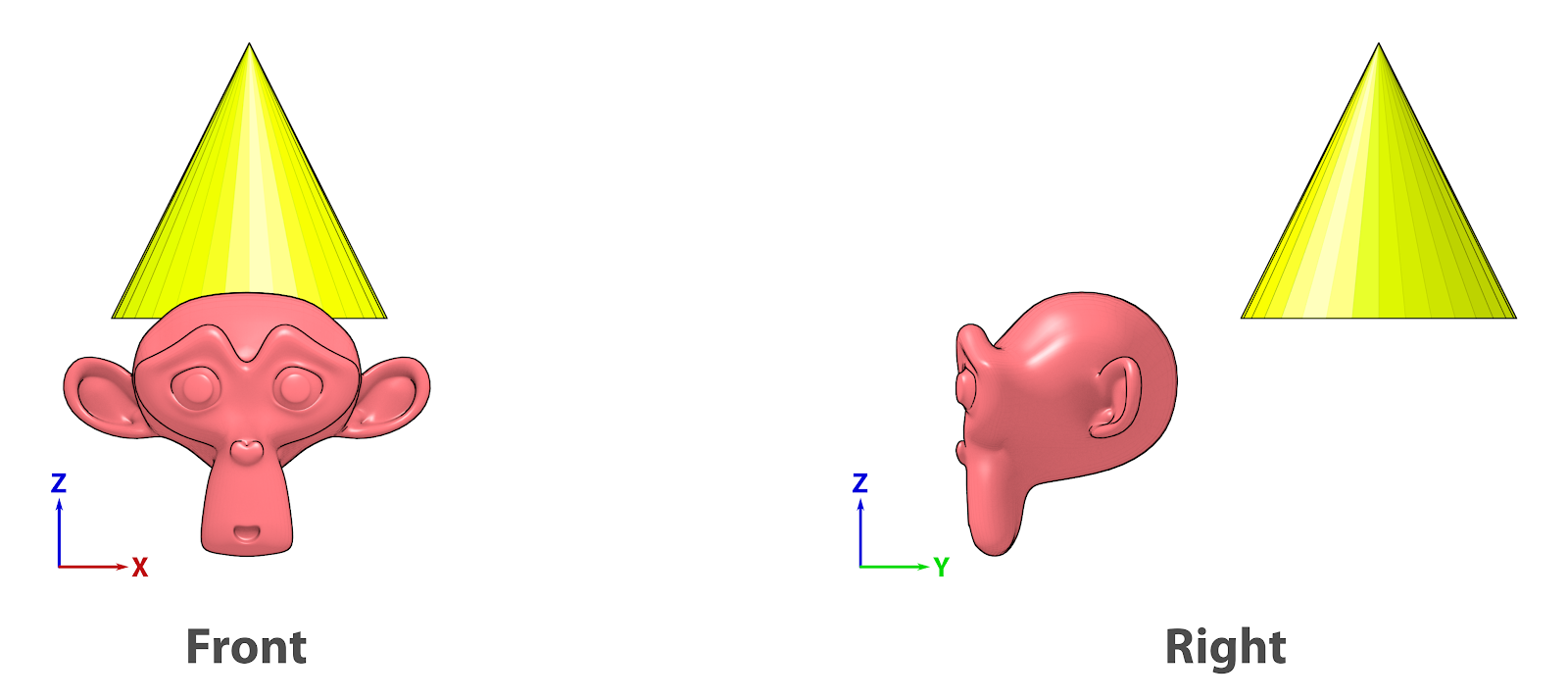
Posição dos objetos em vistas diferentes.¶
Ao tentarem utilizar apenas a visão em perspectiva as dificuldades são muitas, pois é muito difícil aqueles que estão iniciando se localizarem em uma cena 3D. Em seguida lhes é ensinado como utilizar as visualizações ortogonais (frente, direita, topo, etc.). A tendência é que os alunos posicionam o “chapéu” tomando apenas uma vista como referência, nesse caso frente (Front). Só que, ao trocarem a vista para perspectiva, o chapéu aparece deslocado (Fig. 28). Ao visualizarem por outro ponto de vista, como, por exemplo à direita (Right) acabam se dando conta que o objeto está afastado de onde deveria estar. Com o tempo os alunos “pegam o jeito” e trocam o ponto de vista ao trabalharem com o posicionamento de objeto.
Se observarmos o gráfico dos eixos que aparecem à esquerda das figuras, veremos que no caso do Front temos as informações de X e Z, mas falta o Y (justamente a profundidade onde o chapéu se perdeu) e no caso do Right temos Y e Z, mas falta o X. O segredo é sempre orbitar a cena ou alternar os pontos de vista, de modo a ter uma noção clara da estrutura do hambiente, fundamentando assim as suas intervenções futuras.